機械学習の理論と実践をバランスよく学ぶ
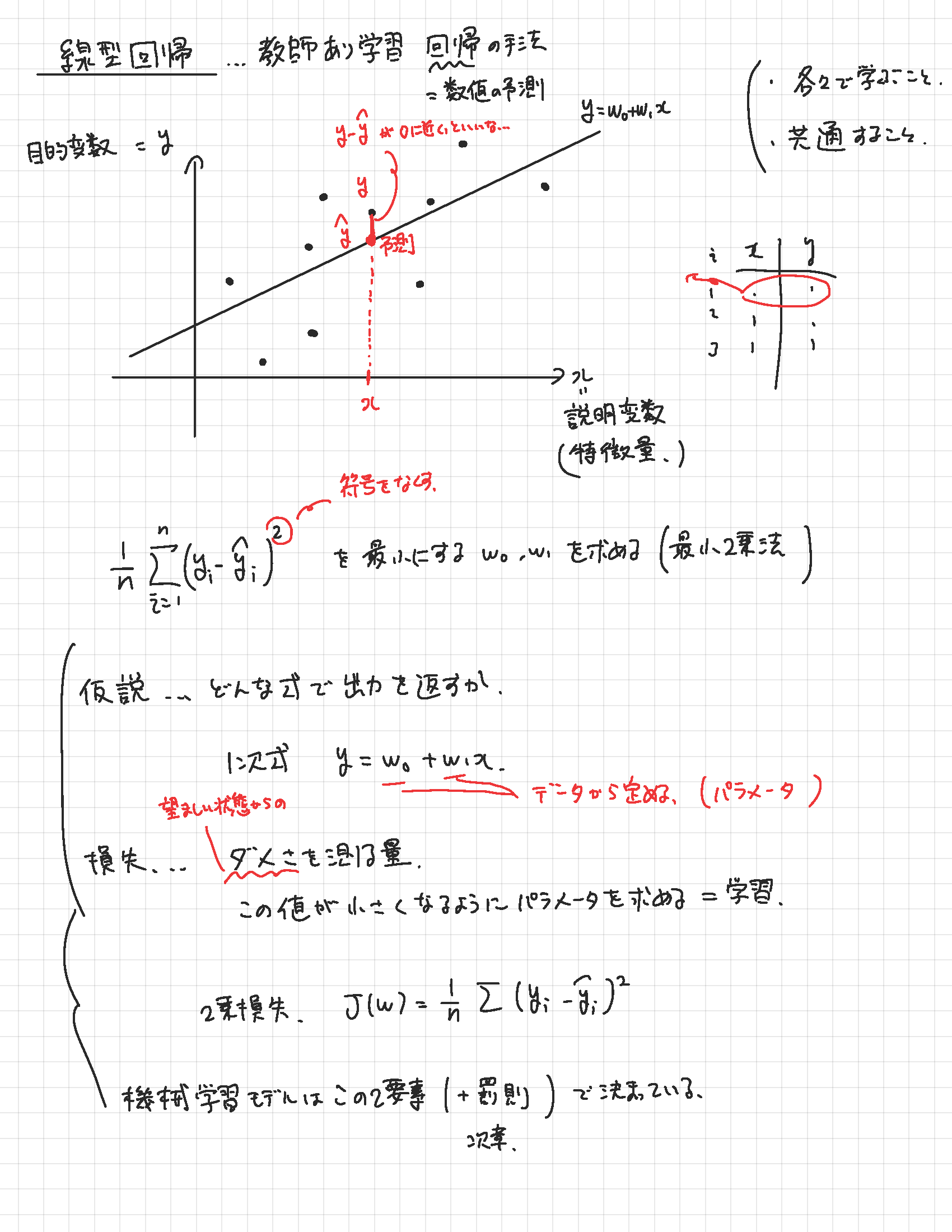
ビジネスや学術の場でのデータ活用において機械学習は非常に重要です。機械学習を使ってできることの中でイメージしやすいのは将来の予測ではないかと思います。しかしデータが持っている構造に光を当てデータそのものの理解を深めるような場面でも機械学習の理論が役立ちます。
本講座ではこのように奥の深い機械学習の理論を丁寧に紹介していきます。理論をきちんと理解するための数学は必要に応じて説明を補いながら進めます。また実装のためのプログラミングはPython言語を用います。初回にチュートリアルを行うので安心してご受講ください。
※2024年度後期(10月ー3月)のご受講、および、アーカイブ講座の動画販売についてお申し込み受付中です。
開講中の講座のアーカイブ視聴による参加、途中参加も可能です。